高可用性
前面我们已经学习了 Prometheus 的使用,了解了基本的 PromQL 语句以及结合 Grafana 来进行监控图表展示,通过 Alertmanager 来进行报警,这些工具结合起来已经可以帮助我们搭建一套比较完整的监控报警系统了,但是也仅仅局限于测试环境,对于生产环境来说则还有许多需要改进的地方,其中一个非常重要的就是 Prometheus 的高可用。
单台的 Prometheus 存在单点故障的风险,随着监控规模的扩大,Prometheus 产生的数据量也会非常大,性能和存储都会面临问题。毋庸置疑,我们需要一套高可用的 Prometheus 集群。
可用性
我们知道 Prometheus 是采用的 Pull 机制获取监控数据,即使使用 Push Gateway 对于 Prometheus 也是 Pull,为了确保 Prometheus 服务的可用性,我们只需要部署多个 Prometheus 实例,然后采集相同的 metrics 数据即可,如下图所示:
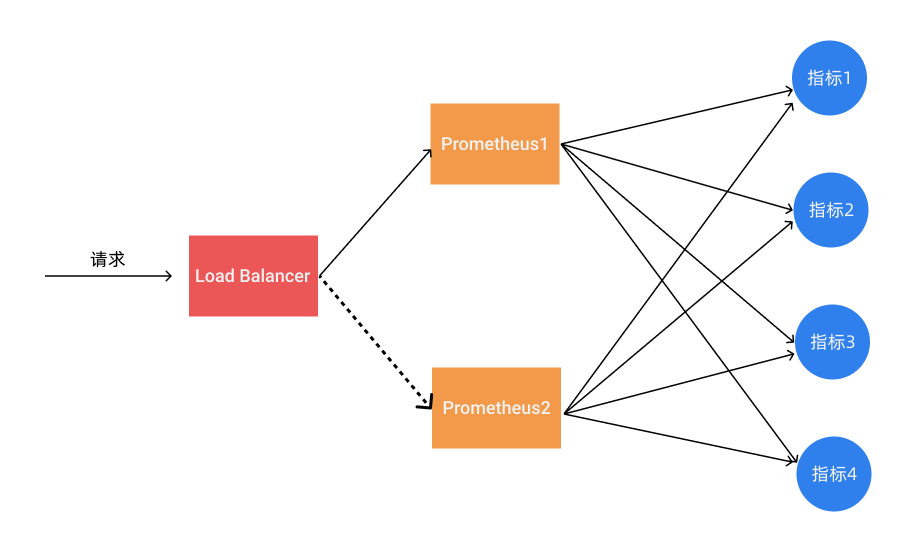
这个方式来满足服务的可用性应该是平时我们使用得最多的一种方式,当一个实例挂掉后从 LB 里面自动剔除掉,而且还有负载均衡的作用,可以降低一个 Prometheus 的压力,但这种模式缺点也是非常明显的,就是不满足数据一致性以及持久化问题,因为 Prometheus 是 Pull 的方式,即使多个实例抓取的是相同的监控指标,也不能保证抓取过来的值就是一致的,更何况在实际的使用过程中还会遇到一些网络延迟问题,所以会造成数据不一致的问题,不过对于监控报警这个场景来说,一般也不会要求数据强一致性,所以这种方式从业务上来说是可以接受的,因为这种数据不一致性影响基本上没什么影响。这种场景适合监控规模不大,只需要保存短周期监控数据的场景。
数据持久化
使用上面的基本 HA 的模式基本上是可以满足监控这个场景,但是还有一个数据持久化的问题,如果其中一个实例数据丢了就没办法呢恢复回来了,这个时候我们就可以为 Prometheus 添加远程存储来保证数据持久化。
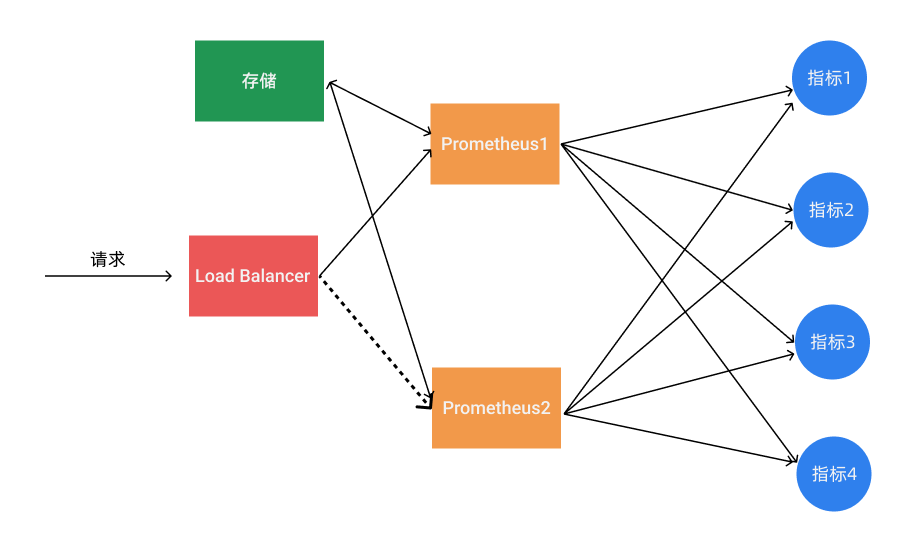
在给 Prometheus 配置上远程存储过后,我们就不用担心数据丢失的问题了,即使当一个 Prometheus 实例宕机或者数据丢失过后,也可以通过远程存储的数据进行恢复。
通过锁获取 Leader
其实上面的基本 HA 加上远程存储的方式基本上可以满足 Prometheus 的高可用了,这种方式的多个 Prometheus 实例都会去定时拉取监控指标数据,然后将热数据存储在本地,然后冷数据同步到远程存储中去,对于大型集群来说频繁的去拉取指标数据势必会对网络造成更大的压力。所以我们也通过服务注册的方式来实现 Prometheus 的高可用性,集群启动的时候每个节点都尝试去获取锁,获取成功的节点成为 Leader 执行任务,若主节点宕机,从节点获取锁成为 Leader 并接管服务。
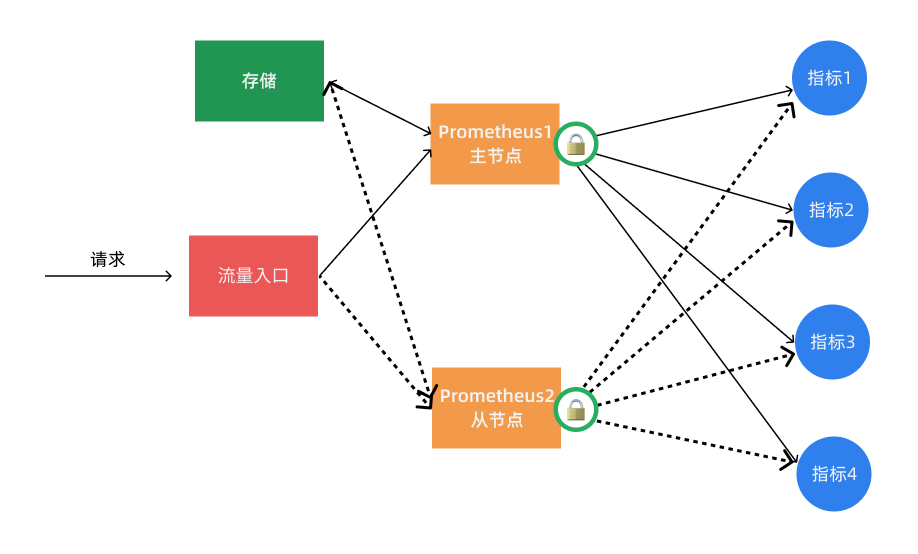
不过这种方案需要我们通过去写代码进行改造,如果在 Kubernetes 中我们完全可以使用自带的 Lease 对象来获取分布式锁 🔒,这不是很困难,只是以后要更新版本稍微麻烦点。
上面的几种方案基本上都可以满足基本的 Prometheus 高可用,但是对于大型集群来说,一个 Prometheus 实例的压力始终非常大。
联邦集群
当单个 Prometheus 实例无法处理大量的采集任务时,这个时候我们就可以使用基于 Prometheus 联邦集群的方式来将监控任务划分到不同的 Prometheus 实例中去。
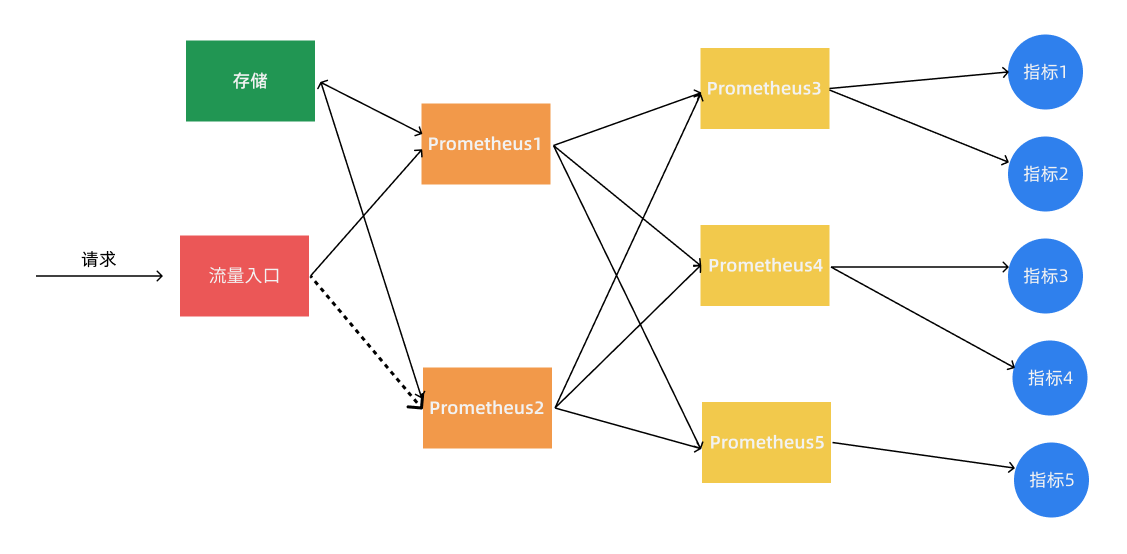
我们可以将不同类型的采集任务划分到不同的 Prometheus 实例中去执行,进行功能分片,比如一个 Prometheus 负责采集节点的指标数据,另外一个 Prometheus 负责采集应用业务相关的监控指标数据,最后在上层通过一个 Prometheus 对数据进行汇总。
具体的采集任务如何去进行分区也没有固定的标准,需要结合实际的业务进行考虑,除了上面的方式之外,还有一种情况就是单个的采集数据量就非常非常大,比如我们要采集上万个节点的监控指标数据,这种情况即使我们已经进行了分区,但是对于单个 Prometheus 来说压力也是非常大的,这个时候我们就需要按照任务的不同实例进行划分,我们通过 Prometheus 的 relabel 功能,通过 hash 取模的方式可以确保当前 Prometheus 只采集当前任务的一部分实例的监控指标。
# 省略其他配置......
relabel_configs:
- source_labels: [__address__]
modulus: 4 # 将节点分片成 4 个组
target_label: __tmp_hash
action: hashmod
- source_labels: [__tmp_hash]
regex: ^1$ # 只抓第2个组中节点的数据(序号0为第1个组)
action: keep
到这里我们基本上就完成了 Prometheus 高可用的改造。对于小规模集群和大规模集群可以采用不同的方案,但是其中有一个非常重要的部分就是远程存储,我们需要保证数据的持久化就必须使用远程存储。所以下面我们将重点介绍下远程存储的使用,这里我们先讲解目前比较流行的方案:Thanos,它完全兼容 Prometheus API,提供统一查询聚合分布式部署 Prometheus 数据的能力,同时也支持数据长期存储到各种对象存储(比如 S3、阿里云 OSS 等)以及降低采样率来加速大时间范围的数据查询。