概述
Prometheus 是一个监控系统和时序数据库,特别适合监控云原生环境,它具有多维数据模型和强大的查询语言,并在一个生态系统中集成了检测、指标收集、服务发现和报警等功能。
本课程将为你从 0 讲解 Prometheus 的基本概念,然后一步一步深入带领你加深对 Prometheus 的理解。
先决条件
本课程的整个演示环境在 CentOS 7.9 上进行测试,但是整个过程基本上不需要很多的改动就可以移植到其他 Linux 发行版中。
所以在学习本课程之前你将需要有 Unix/Linux 服务器管理的基础知识,系统监控经验会有所帮助,但并不是必须要的,不需要你具有 Prometheus 本身的经验,因为我们本身就是从 0 开始讲解的,所以你不用担心。
什么是 Prometheus
Prometheus 是一个基于指标监控和报警的工具栈。 Prometheus 起源于 SoundCloud ,因为微服务迅速发展,导致实例数量以几何倍数递增,不得不考虑设计一个符合以下几个功能的监控系统:
- 多维数据模型,可以按照实例,服务,端点和方法之类的维度随意对数据进行切片和切块。
- 操作简单,可以随时随地部署监控服务,甚至在本地工作站上,而无需设置分布式存储后端或重新配置环境。
- 可扩展的数据收集和分散的架构,以便于可以可靠的监控服务的许多实例,独立团队可以部署独立的监控服务。
- 一种查询语言,可以利用数据模型进行有效的报警和图形展示。
但是,当时的情况是,以上的功能都分散在各个系统之中,直到 2012 年 SoundCloud 启动了一个孵化项目把这些所有功能集合到一起,也就是 Prometheus。Prometheus 是用 Go 语言编写,从一开始就是开源的,到 2016 年 Prometheus 成为继 Kubernetes 之后,成为 CNCF 的第二个成员。
到现在为止 Prometheus 提供的工具或与其他生态系统组件集成可以提供完整的监控管道:
- 检测(跟踪和暴露指标)
- 指标收集
- 指标存储
- 查询指标,用于报警、仪表板等
Prometheus 具有足够的通用性,可以监控各个级别的实例:你自己的应用程序、第三方服务、主机或网络设备等等。此外 Prometheus 特别适用于监控动态云环境和 Kubernetes 云原生环境。
但是也需要注意的是 Prometheus 并不是万能的,目前并没有解决下面的一些问题:
- 日志和追踪(Prometheus 只处理指标,也称为时间序列)
- 基于机器学习或 AI 的异常检测
- 水平扩展、集群化的存储
这些功能显然也是非常有价值的,但是 Prometheus 本身并没有尝试去解决,而是留给了第三方解决方案。
但是整体来说与其他监控解决方案相比,Prometheus 提供了许多重要功能:
- 多维数据模型,允许对指标进行跟踪
- 强大的查询语言(PromQL)
- 时间序列处理和报警的整合
- 与服务发现集成来确定应监控的内容
- 操作简单
- 执行高效
尽管这些功能中的许多功能如今在监控系统中变得越来越普遍,但是 Prometheus 是第一个将所有功能组合在一起的开源解决方案。
操作简单
Prometheus 的整个概念很简单并且操作也非常简单。 Prometheus 用 Go 编写,直接使用独立的二进制文件即可部署,而无需依赖外部运行时(例如 JVM)、解释器(例如 Python 或 Ruby)或共享系统库。
每个 Prometheus 服务器都独立于任何其他 Prometheus 服务器收集数据并评估报警规则,并且仅在本地存储数据,而没有严格的集群或副本。
要创建用于报警的高可用性配置,你仍然可以运行两个配置相同的 Prometheus 服务器,以计算相同的报警(Alertmanager 将对通知进行去重操作):
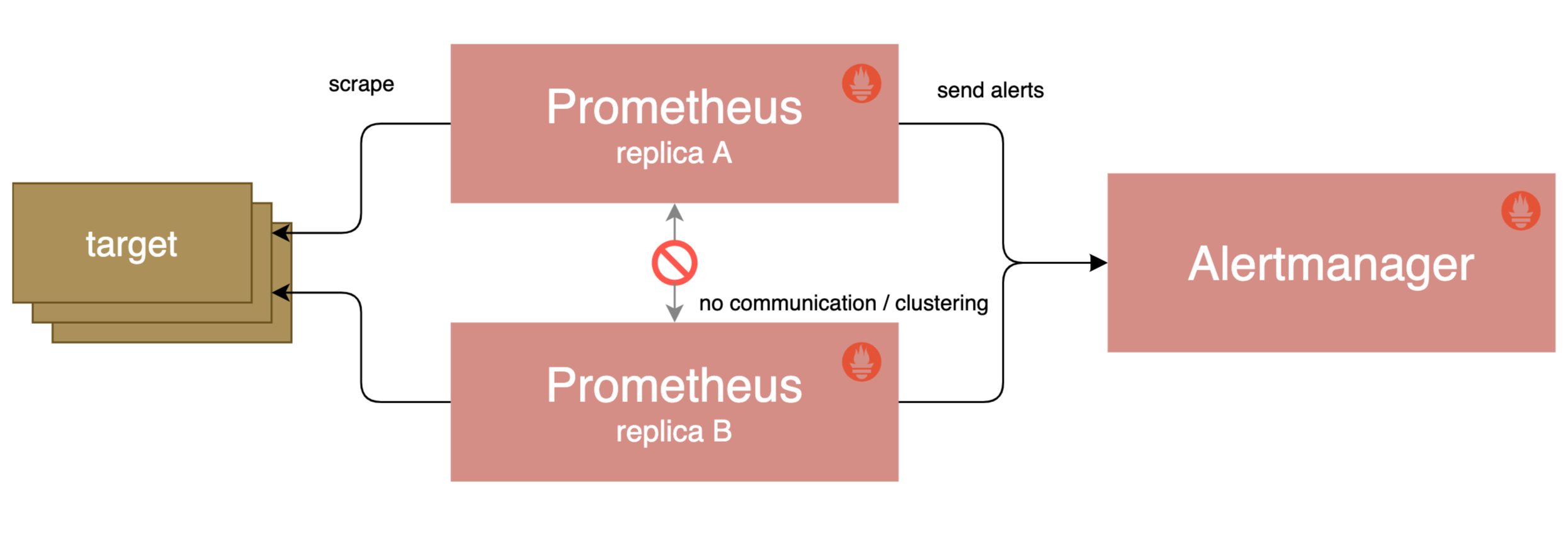
当然,Prometheus 的大规模部署还是非常复杂的,在后面的章节中接触到,此外 Prometheus 还暴露了一些接口,允许第三方开发者来解决一些问题,比如远程存储这些功能。
性能高效
Prometheus 需要能够同时从许多系统和服务中收集详细的指标数据,为此,特别对以下组件进行了高度优化:
- 抓取和解析传入的指标
- 写入和读取时序数据库
- 评估基于 TSDB 数据的 PromQL 表达式
根据社区的使用经验显示,一台大型 Prometheus 服务器每秒可以摄取多达 100万 个时间序列样本,并使用 1-2 字节来将每个样本存储在磁盘上。