Pod 生命周期
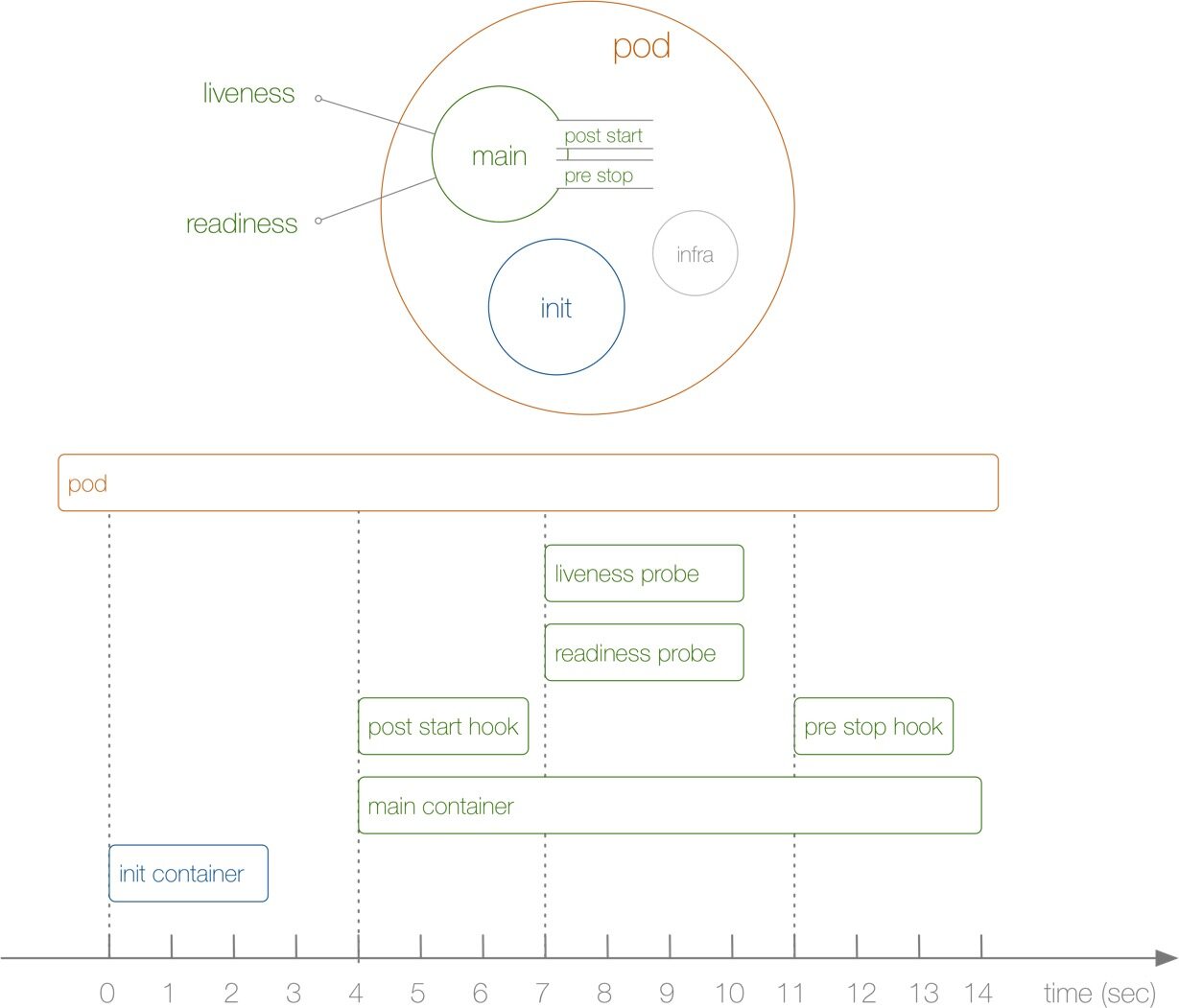
前面我们已经了解了 Pod 的设计原理,接下来我们来了解下 Pod 的生命周期。下图展示了一个 Pod 的完整生命周期过程,其中包含 Init Container、Pod Hook、健康检查 三个主要部分,接下来我们就来分别介绍影响 Pod 生命周期的部分:
首先在介绍 Pod 的生命周期之前,我们先了解下 Pod 的状态,因为 Pod 状态可以反应出当前我们的 Pod 的具体状态信息,也是我们分析排错的一个必备的方式。
Pod 状态
首先先了解下 Pod 的状态值,我们可以通过 kubectl explain pod.status 命令来了解关于 Pod 状态的一些信息,Pod 的状态定义在 PodStatus 对象中,其中有一个 phase 字段,下面是 phase 的可能取值:
- 挂起(Pending):Pod 信息已经提交给了集群,但是还没有被调度器调度到合适的节点或者 Pod 里的镜像正在下载
- 运行中(Running):该 Pod 已经绑定到了一个节点上,Pod 中所有的容器都已被创建。至少有一个容器正在运行,或者正处于启动或重启状态
- 成功(Succeeded):Pod 中的所有容器都被成功终止,并且不会再重启
- 失败(Failed):Pod 中的所有容器都已终止了,并且至少有一个容器是因为失败终止。也就是说,容器以非
0状态退出或者被系统终止 - 未知(Unknown):因为某些原因无法取得 Pod 的状态,通常是因为与 Pod 所在主机通信失败导致的
除此之外,PodStatus 对象中还包含一个 PodCondition 的数组,里面包含的属性有:
- lastProbeTime:最后一次探测 Pod Condition 的时间戳。
- lastTransitionTime:上次 Condition 从一种状态转换到另一种状态的时间。
- message:上次 Condition 状态转换的详细描述。
- reason:Condition 最后一次转换的原因。
- status:Condition 状态类型,可以为 “True”, “False”, and “Unknown”.
- type:Condition 类型,包括以下方面:
- PodScheduled(Pod 已经被调度到其他 node 里)
- Ready(Pod 能够提供服务请求,可以被添加到所有可匹配服务的负载平衡池中)
- Initialized(所有的
init containers已经启动成功) - Unschedulable(调度程序现在无法调度 Pod,例如由于缺乏资源或其他限制)
- ContainersReady(Pod 里的所有容器都是 ready 状态)
重启策略
我们可以通过配置 restartPolicy 字段来设置 Pod 中所有容器的重启策略,其可能值为 Always、OnFailure 和 Never,默认值为 Always,restartPolicy 指通过 kubelet 在同一节点上重新启动容器。通过 kubelet 重新启动的退出容器将以指数增加延迟(10s,20s,40s…)重新启动,上限为 5 分钟,并在成功执行 10 分钟后重置。不同类型的的控制器可以控制 Pod 的重启策略:
Job:适用于一次性任务如批量计算,任务结束后 Pod 会被此类控制器清除。Job 的重启策略只能是"OnFailure"或者"Never"。ReplicaSet、Deployment:此类控制器希望 Pod 一直运行下去,它们的重启策略只能是"Always"。DaemonSet:每个节点上启动一个 Pod,很明显此类控制器的重启策略也应该是"Always"。
初始化容器
了解了 Pod 状态后,首先来了解下 Pod 中最新启动的 Init Container,也就是我们平时常说的初始化容器。Init Container就是用来做初始化工作的容器,可以是一个或者多个,如果有多个的话,这些容器会按定义的顺序依次执行。我们知道一个 Pod 里面的所有容器是共享数据卷和 Network Namespace 的,所以 Init Container 里面产生的数据可以被主容器使用到。从上面的 Pod 生命周期的图中可以看出初始化容器是独立与主容器之外的,只有所有的`初始化容器执行完之后,主容器才会被启动。那么初始化容器有哪些应用场景呢:
- 等待其他模块 Ready:这个可以用来解决服务之间的依赖问题,比如我们有一个 Web 服务,该服务又依赖于另外一个数据库服务,但是在我们启动这个 Web 服务的时候我们并不能保证依赖的这个数据库服务就已经启动起来了,所以可能会出现一段时间内 Web 服务连接数据库异常。要解决这个问题的话我们就可以在 Web 服务的 Pod 中使用一个
InitContainer,在这个初始化容器中去检查数据库是否已经准备好了,准备好了过后初始化容器就结束退出,然后我们主容器的 Web 服务才被启动起来,这个时候去连接数据库就不会有问题了。 - 做初始化配置:比如集群里检测所有已经存在的成员节点,为主容器准备好集群的配置信息,这样主容器起来后就能用这个配置信息加入集群。
- 其它场景:如将 Pod 注册到一个中央数据库、配置中心等。
比如现在我们来实现一个功能,在 Nginx Pod 启动之前去重新初始化首页内容,如下所示的资源清单:(init-pod.yaml)
apiVersion: v1
kind: Pod
metadata:
name: init-demo
spec:
volumes:
- name: workdir
emptyDir: {}
initContainers:
- name: install
image: busybox
command:
- wget
- '-O'
- '/work-dir/index.html'
- http://www.baidu.com # https
volumeMounts:
- name: workdir
mountPath: '/work-dir'
containers:
- name: web
image: nginx
ports:
- containerPort: 80
volumeMounts:
- name: workdir
mountPath: /usr/share/nginx/html
上面的资源清单中我们首先在 Pod 顶层声明了一个名为 workdir 的 Volume,前面我们用了 hostPath 的模式,这里我们使用的是 emptyDir{},这个是一个临时的目录,数据会保存在 kubelet 的工作目录下面,生命周期等同于 Pod 的生命周期。
然后我们定义了一个初始化容器,该容器会下载一个 html 文件到 /work-dir 目录下面,但是由于我们又将该目录声明挂载到了全局的 Volume,同样的主容器 nginx 也将目录 /usr/share/nginx/html 声明挂载到了全局的 Volume,所以在主容器的该目录下面会同步初始化容器中创建的 index.html 文件。
直接创建上面的 Pod:
➜ ~ kubectl apply -f init-pod.yaml
创建完成后可以查看该 Pod 的状态:
➜ ~ kubectl get pods
NAME READY STATUS RESTARTS AGE
init-demo 0/1 Init:0/1 0 4s
可以发现 Pod 现在的状态处于 Init:0/1 状态,意思就是现在第一个初始化容器还在执行过程中,此时我们可以查看 Pod 的详细信息:
➜ ~ kubectl describe pod init-demo
Name: init-demo
Namespace: default
Priority: 0
Node: node1/192.168.31.108
Start Time: Mon, 01 Nov 2021 18:58:40 +0800
Labels: <none>
Annotations: <none>
Status: Running
IP: 10.244.1.10
IPs:
IP: 10.244.1.10
Init Containers:
install:
Container ID: containerd://ca0020473b613729e4c853cd0c163023677a631432531ceacbb1aed1ae65bea9
Image: busybox
Image ID: docker.io/library/busybox@sha256:15e927f78df2cc772b70713543d6b651e3cd8370abf86b2ea4644a9fba21107f
Port: <none>
Host Port: <none>
Command:
wget
-O
/work-dir/index.html
http://www.baidu.com
State: Terminated
Reason: Completed
Exit Code: 0
Started: Mon, 01 Nov 2021 18:58:43 +0800
Finished: Mon, 01 Nov 2021 18:58:43 +0800
Ready: True
Restart Count: 0
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-htmjf (ro)
/work-dir from workdir (rw)
Containers:
web:
Container ID: containerd://18f08b312af9c464f8cc1313b82cfaf05d1910c8dc35d91dddd2810a184a0bfd
Image: nginx
Image ID: docker.io/library/nginx@sha256:644a70516a26004c97d0d85c7fe1d0c3a67ea8ab7ddf4aff193d9f301670cf36
Port: 80/TCP
Host Port: 0/TCP
State: Running
Started: Mon, 01 Nov 2021 18:58:59 +0800
Ready: True
Restart Count: 0
Environment: <none>
Mounts:
/usr/share/nginx/html from workdir (rw)
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-htmjf (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
workdir:
Type: EmptyDir (a temporary directory that shares a pod's lifetime)
Medium:
SizeLimit: <unset>
kube-api-access-htmjf:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMapOptional: <nil>
DownwardAPI: true
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 34s default-scheduler Successfully assigned default/init-demo to node1
Normal Pulling 35s kubelet Pulling image "busybox"
Normal Pulled 32s kubelet Successfully pulled image "busybox" in 2.655408135s
Normal Created 32s kubelet Created container install
Normal Started 32s kubelet Started container install
Normal Pulling 31s kubelet Pulling image "nginx"
Normal Pulled 16s kubelet Successfully pulled image "nginx" in 15.385097955s
Normal Created 16s kubelet Created container web
Normal Started 16s kubelet Started container web
从上面的描述信息里面可以看到初始化容器已经启动了,现在处于 Running 状态,所以还需要稍等,到初始化容器执行完成后退出初始化容器会变成 Completed 状态,然后才会启动主容器。待到主容器也启动完成后,Pod 就会变成Running 状态,然后我们去访问下 Pod 主页,验证下是否有我们初始化容器中下载的页面信息:
➜ ~ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
init-demo 1/1 Running 0 70s 10.244.1.10 node1 <none> <none>
➜ ~ curl 10.244.1.10
<!DOCTYPE html>
<!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=text/css href=http://s1.bdstatic.com/r/www/cache/bdorz/baidu.min.css><title>百度一下,你就知道</title></head> <body link=#0000cc> <div id=wrapper> <div id=head> <div class=head_wrapper> <div class=s_form> <div class=s_form_wrapper> <div id=lg> <img hidefocus=true src=//www.baidu.com/img/bd_logo1.png width=270 height=129> </div> <form id=form name=f action=//www.baidu.com/s class=fm> <input type=hidden name=bdorz_come value=1> <input type=hidden name=ie value=utf-8> <input type=hidden name=f value=8> <input type=hidden name=rsv_bp value=1> <input type=hidden name=rsv_idx value=1> <input type=hidden name=tn value=baidu><span class="bg s_ipt_wr"><input id=kw name=wd class=s_ipt value maxlength=255 autocomplete=off autofocus></span><span class="bg s_btn_wr"><input type=submit id=su value=百度一下 class="bg s_btn"></span> </form> </div> </div> <div id=u1> <a href=http://news.baidu.com name=tj_trnews class=mnav>新闻</a> <a href=http://www.hao123.com name=tj_trhao123 class=mnav>hao123</a> <a href=http://map.baidu.com name=tj_trmap class=mnav>地图</a> <a href=http://v.baidu.com name=tj_trvideo class=mnav>视频</a> <a href=http://tieba.baidu.com name=tj_trtieba class=mnav>贴吧</a> <noscript> <a href=http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1 name=tj_login class=lb>登录</a> </noscript> <script>document.write('<a href="http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u='+ encodeURIComponent(window.location.href+ (window.location.search === "" ? "?" : "&")+ "bdorz_come=1")+ '" name="tj_login" class="lb">登录</a>');</script> <a href=//www.baidu.com/more/ name=tj_briicon class=bri style="display: block;">更多产品</a> </div> </div> </div> <div id=ftCon> <div id=ftConw> <p id=lh> <a href=http://home.baidu.com>关于百度</a> <a href=http://ir.baidu.com>About Baidu</a> </p> <p id=cp>©2017 Baidu <a href=http://www.baidu.com/duty/>使用百度前必读</a> <a href=http://jianyi.baidu.com/ class=cp-feedback>意见反馈</a> 京ICP证030173号 <img src=//www.baidu.com/img/gs.gif> </p> </div> </div> </div> </body> </html>
Pod Hook
我们知道 Pod 是 Kubernetes 集群中的最小单元,而 Pod 是由容器组成的,所以在讨论 Pod 的生命周期的时候我们可以先来讨论下容器的生命周期。实际上 Kubernetes 为我们的容器提供了生命周期的钩子,就是我们说的 Pod Hook,Pod Hook 是由 kubelet 发起的,当容器中的进程启动前或者容器中的进程终止之前运行,这是包含在容器的生命周期之中。我们可以同时为 Pod 中的所有容器都配置 hook。
Kubernetes 为我们提供了两种钩子函数:
PostStart:这个钩子在容器创建后立即执行。但是,并不能保证钩子将在容器ENTRYPOINT之前运行,因为没有参数传递给处理程序。主要用于资源部署、环境准备等。不过需要注意的是如果钩子花费太长时间以至于不能运行或者挂起,容器将不能达到 running 状态。PreStop:这个钩子在容器终止之前立即被调用。它是阻塞的,意味着它是同步的,所以它必须在删除容器的调用发出之前完成。主要用于优雅关闭应用程序、通知其他系统等。如果钩子在执行期间挂起,Pod 阶段将停留在 running 状态并且永不会达到 failed 状态。
如果 PostStart 或者 PreStop 钩子失败, 它会杀死容器。所以我们应该让钩子函数尽可能的轻量。当然有些情况下,长时间运行命令是合理的, 比如在停止容器之前预先保存状态。
另外我们有两种方式来实现上面的钩子函数:
Exec- 用于执行一段特定的命令,不过要注意的是该命令消耗的资源会被计入容器。HTTP- 对容器上的特定的端点执行 HTTP 请求。
以下示例中,定义了一个 Nginx Pod,其中设置了 PostStart 钩子函数,即在容器创建成功后,写入一句话到 /usr/share/message 文件中:
# pod-poststart.yaml
apiVersion: v1
kind: Pod
metadata:
name: hook-demo1
spec:
containers:
- name: hook-demo1
image: nginx
lifecycle:
postStart:
exec:
command:
[
'/bin/sh',
'-c',
'echo Hello from the postStart handler > /usr/share/message',
]
直接创建上面的 Pod:
➜ ~ kubectl apply -f pod-poststart.yaml
➜ ~ kubectl get pods
NAME READY STATUS RESTARTS AGE
hook-demo1 1/1 Running 0 26s
创建成功后可以查看容器中 /usr/share/message 文件是否内容正确:
➜ ~ kubectl exec -it hook-demo1 -- cat /usr/share/message
Hello from the postStart handler
当用户请求删除含有 Pod 的资源对象时(如 Deployment 等),K8S 为了让应用程序优雅关闭(即让应用程序完成正在处理的请求后,再关闭软件),K8S 提供两种信息通知:
- 默认:K8S 通知 node 执行容器
stop命令,容器运行时会先向容器中 PID 为 1 的进程发送系统信号SIGTERM,然后等待容器中的应用程序终止执行,如果等待时间达到设定的超时时间,或者默认超时时间(30s),会继续发送SIGKILL的系统信号强行 kill 掉进程 - 使用 Pod 生命周期(利用
PreStop回调函数),它在发送终止信号之前执行
默认所有的优雅退出时间都在 30 秒内,kubectl delete 命令支持 --grace-period=<seconds> 选项,这个选项允许用户用他们自己指定的值覆盖默认值,值0代表强制删除 pod。 在 kubectl 1.5 及以上的版本里,执行强制删除时必须同时指定 --force --grace-period=0。
强制删除一个 pod 是从集群中还有 etcd 里立刻删除这个 pod,只是当 Pod 被强制删除时, APIServer 不会等待来自 Pod 所在节点上的 kubelet 的确认信息:pod 已经被终止。在 API 里 pod 会被立刻删除,在节点上, pods 被设置成立刻终止后,在强行杀掉前还会有一个很小的宽限期。
以下示例中,定义了一个 Nginx Pod,其中设置了 PreStop 钩子函数,即在容器退出之前,优雅的关闭 Nginx:
# pod-prestop.yaml
apiVersion: v1
kind: Pod
metadata:
name: hook-demo2
spec:
containers:
- name: hook-demo2
image: nginx
lifecycle:
preStop:
exec:
command: ['/usr/sbin/nginx', '-s', 'quit'] # 优雅退出
---
apiVersion: v1
kind: Pod
metadata:
name: hook-demo3
spec:
volumes:
- name: message
hostPath:
path: /tmp
containers:
- name: hook-demo2
image: nginx
ports:
- containerPort: 80
volumeMounts:
- name: message
mountPath: /usr/share/
lifecycle:
preStop:
exec:
command:
[
'/bin/sh',
'-c',
'echo Hello from the preStop Handler > /usr/share/message',
]
上面定义的两个 Pod,一个是利用 preStop 来进行优雅删除,另外一个是利用 preStop 来做一些信息记录的事情,同样直接创建上面的 Pod:
➜ ~ kubectl apply -f pod-prestop.yaml
➜ ~ kubectl get pods
NAME READY STATUS RESTARTS AGE
hook-demo2 1/1 Running 0 20s
hook-demo3 1/1 Running 0 20s
创建完成后,我们可以直接删除 hook-demo2 这个 Pod,在容器删除之前会执行 preStop 里面的优雅关闭命令,这个用法在后面我们的滚动更新的时候用来保证我们的应用零宕机非常有用。第二个 Pod 我们声明了一个 hostPath 类型的 Volume,在容器里面声明挂载到了这个 Volume,所以当我们删除 Pod,退出容器之前,在容器里面输出的信息也会同样的保存到宿主机(一定要是 Pod 被调度到的目标节点)的 /tmp 目录下面,我们可以查看 hook-demo3 这个 Pod 被调度的节点:
➜ ~ kubectl describe pod hook-demo3
Name: hook-demo3
Namespace: default
Priority: 0
Node: node1/192.168.31.108
......
可以看到这个 Pod 被调度到了 node1 这个节点上,我们可以先到该节点上查看 /tmp 目录下面目前没有任何内容:
➜ ~ ls /tmp/
现在我们来删除 hook-demo3 这个 Pod,安装我们的设定在容器退出之前会执行 preStop 里面的命令,也就是会往 message 文件中输出一些信息:
➜ ~ kubectl delete pod hook-demo3
pod "hook-demo3" deleted
➜ ~ ls /tmp/
message
➜ ~ cat /tmp/message
Hello from the preStop Handler
另外 Hook 调用的日志没有暴露给 Pod,所以只能通过 describe 命令来获取,如果有错误将可以看到 FailedPostStartHook 或 FailedPreStopHook 这样的 event。
Pod 健康检查
现在在 Pod 的整个生命周期中,能影响到 Pod 的就只剩下健康检查这一部分了。在 Kubernetes 集群当中,我们可以通过配置liveness probe(存活探针)和 readiness probe(可读性探针) 来影响容器的生命周期:
- kubelet 通过使用
liveness probe来确定你的应用程序是否正在运行,通俗点将就是是否还活着。一般来说,如果你的程序一旦崩溃了, Kubernetes 就会立刻知道这个程序已经终止了,然后就会重启这个程序。而我们的liveness probe的目的就是来捕获到当前应用程序还没有终止,还没有崩溃,如果出现了这些情况,那么就重启处于该状态下的容器,使应用程序在存在 bug 的情况下依然能够继续运行下去。 - kubelet 使用
readiness probe来确定容器是否已经就绪可以接收流量过来了。这个探针通俗点讲就是说是否准备好了,现在可以开始工作了。只有当 Pod 中的容器都处于就绪状态的时候 kubelet 才会认定该 Pod 处于就绪状态,因为一个 Pod 下面可能会有多个容器。当然 Pod 如果处于非就绪状态,那么我们就会将他从 Service 的 Endpoints 列表中移除出来,这样我们的流量就不会被路由到这个 Pod 里面来了。
和前面的钩子函数一样的,我们这两个探针的支持下面几种配置方式:
exec:执行一段命令http:检测某个 http 请求tcpSocket:使用此配置,kubelet 将尝试在指定端口上打开容器的套接字。如果可以建立连接,容器被认为是健康的,如果不能就认为是失败的。实际上就是检查端口。
我们先来给大家演示下存活探针的使用方法,首先我们用 exec 执行命令的方式来检测容器的存活,如下:
# liveness-exec.yaml
apiVersion: v1
kind: Pod
metadata:
name: liveness-exec
spec:
containers:
- name: liveness
image: busybox
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5
我们这里需要用到一个新的属性 livenessProbe,下面通过 exec 执行一段命令:
periodSeconds:表示让 kubelet 每隔 5 秒执行一次存活探针,也就是每 5 秒执行一次上面的cat /tmp/healthy命令,如果命令执行成功了,将返回 0,那么 kubelet 就会认为当前这个容器是存活的,如果返回的是非 0 值,那么 kubelet 就会把该容器杀掉然后重启它。默认是 10 秒,最小 1 秒。initialDelaySeconds:表示在第一次执行探针的时候要等待 5 秒,这样能够确保我们的容器能够有足够的时间启动起来。大家可以想象下,如果你的第一次执行探针等候的时间太短,是不是很有可能容器还没正常启动起来,所以存活探针很可能始终都是失败的,这样就会无休止的重启下去了,对吧?
我们在容器启动的时候,执行了如下命令:
/bin/sh -c "touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600"
意思是说在容器最开始的 30 秒内创建了一个 /tmp/healthy 文件,在这 30 秒内执行 cat /tmp/healthy 命令都会返回一个成功的返回码。30 秒后,我们删除这个文件,现在执行 cat /tmp/healthy 是不是就会失败了(默认检测失败 3 次才认为失败),所以这个时候就会重启容器了。
我们来创建下该 Pod,然后在 30 秒内,查看 Pod 的 Event:
➜ ~ kubectl apply -f liveness-exec.yaml
➜ ~ kubectl describe pod liveness-exec
Name: liveness-exec
Namespace: default
......
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 68s default-scheduler Successfully assigned default/liveness-exec to node1
Normal Pulling 68s kubelet Pulling image "busybox"
Normal Pulled 52s kubelet Successfully pulled image "busybox" in 15.352808024s
Normal Created 52s kubelet Created container liveness
Normal Started 52s kubelet Started container liveness
Warning Unhealthy 8s (x3 over 18s) kubelet Liveness probe failed: cat: can't open '/tmp/healthy': No such file or directory
Normal Killing 8s kubelet Container liveness failed liveness probe, will be restarted
我们可以观察到容器是正常启动的,在隔一会儿,比如 40s 后,再查看下 Pod 的 Event,在最下面有一条信息显示 liveness probe 失败了,容器将要重启。然后可以查看到 Pod 的 RESTARTS 值加 1 了:
➜ ~ kubectl get pods
NAME READY STATUS RESTARTS AGE
liveness-exec 1/1 Running 1 (16s ago) 106s
同样的,我们还可以使用HTTP GET请求来配置我们的存活探针,我们这里使用一个 liveness 镜像来验证演示下:
# liveness-http.yaml
apiVersion: v1
kind: Pod
metadata:
name: liveness-http
spec:
containers:
- name: liveness
image: cnych/liveness
args:
- /server
livenessProbe:
httpGet:
path: /healthz
port: 8080
httpHeaders:
- name: X-Custom-Header
value: Awesome
initialDelaySeconds: 3
periodSeconds: 3
同样的,根据 periodSeconds 属性我们可以知道 kubelet 需要每隔 3 秒执行一次 liveness Probe,该探针将向容器中的 server 的 8080 端口发送一个 HTTP GET 请求。如果 server 的 /healthz 路径的 handler 返回一个成功的返回码,kubelet 就会认定该容器是活着的并且很健康,如果返回失败的返回码,kubelet 将杀掉该容器并重启它。initialDelaySeconds 指定 kubelet 在该执行第一次探测之前需要等待 3 秒钟。
通常来说,任何大于200小于400的状态码都会认定是成功的返回码。其他返回码都会被认为是失败的返回码。
我们可以来查看下上面的 healthz 的实现:
http.HandleFunc("/healthz", func(w http.ResponseWriter, r *http.Request) {
duration := time.Now().Sub(started)
if duration.Seconds() > 10 {
w.WriteHeader(500)
w.Write([]byte(fmt.Sprintf("error: %v", duration.Seconds())))
} else {
w.WriteHeader(200)
w.Write([]byte("ok"))
}
})
大概意思就是最开始前 10s 返回状态码 200,10s 过后就返回状态码 500。所以当容器启动 3 秒后,kubelet 开始执行健康检查。第一次健康检查会成功,因为是在 10s 之内,但是 10 秒后,健康检查将失败,因为现在返回的是一个错误的状态码了,所以 kubelet 将会杀掉和重启容器。
同样的,我们来创建下该 Pod 测试下效果,10 秒后,查看 Pod 的 event,确认 liveness probe 失败并重启了容器:
➜ ~ kubectl apply -f liveness-http.yaml
➜ ~ kubectl describe pod liveness-http
Name: liveness-http
Namespace: default
......
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 44s default-scheduler Successfully assigned default/liveness-http to node2
Normal Pulled 41s kubelet Successfully pulled image "cnych/liveness" in 3.359937074s
Normal Pulling 21s (x2 over 45s) kubelet Pulling image "cnych/liveness"
Warning Unhealthy 21s (x3 over 29s) kubelet Liveness probe failed: HTTP probe failed with statuscode: 500
Normal Killing 21s kubelet Container liveness failed liveness probe, will be restarted
Normal Created 6s (x2 over 41s) kubelet Created container liveness
Normal Started 6s (x2 over 41s) kubelet Started container liveness
Normal Pulled 6s kubelet Successfully pulled image "cnych/liveness" in 15.300179047s
➜ ~ kubectl get pods
NAME READY STATUS RESTARTS AGE
liveness-http 1/1 Running 2 (16s ago) 76s
除了上面的 exec 和 httpGet 两种检测方式之外,还可以通过 tcpSocket 方式来检测端口是否正常,大家可以按照上面的方式结合 kubectl explain 命令自己来验证下这种方式。
另外前面我们提到了探针里面有一个 initialDelaySeconds 的属性,可以来配置第一次执行探针的等待时间,对于启动非常慢的应用这个参数非常有用,比如 Jenkins、Gitlab 这类应用,但是如何设置一个合适的初始延迟时间呢?这个就和应用具体的环境有关系了,所以这个值往往不是通用的,这样的话可能就会导致一个问题,我们的资源清单在别的环境下可能就会健康检查失败了,为解决这个问题,在 Kubernetes v1.16 版本官方特地新增了一个 startupProbe(启动探针),该探针将推迟所有其他探针,直到 Pod 完成启动为止,使用方法和存活探针一样:
startupProbe:
httpGet:
path: /healthz
port: 8080
failureThreshold: 30 # 尽量设置大点
periodSeconds: 10
比如上面这里的配置表示我们的慢速容器最多可以有 5 分钟(30 个检查 * 10 秒= 300s)来完成启动。
有的时候,应用程序可能暂时无法对外提供服务,例如,应用程序可能需要在启动期间加载大量数据或配置文件。在这种情况下,您不想杀死应用程序,也不想对外提供服务。那么这个时候我们就可以使用 readiness probe 来检测和减轻这些情况,Pod 中的容器可以报告自己还没有准备,不能处理 Kubernetes 服务发送过来的流量。readiness probe 的配置跟 liveness probe 基本上一致的,唯一的不同是使用 readinessProbe 而不是 livenessProbe,两者如果同时使用的话就可以确保流量不会到达还未准备好的容器,准备好过后,如果应用程序出现了错误,则会重新启动容器。对于就绪探针我们会在后面 Service 的章节和大家继续介绍。
另外除了上面的 initialDelaySeconds 和 periodSeconds 属性外,探针还可以配置如下几个参数:
timeoutSeconds:探测超时时间,默认 1 秒,最小 1 秒。successThreshold:探测失败后,最少连续探测成功多少次才被认定为成功,默认是 1,但是如果是liveness则必须是 1。最小值是 1。failureThreshold:探测成功后,最少连续探测失败多少次才被认定为失败,默认是 3,最小值是 1。